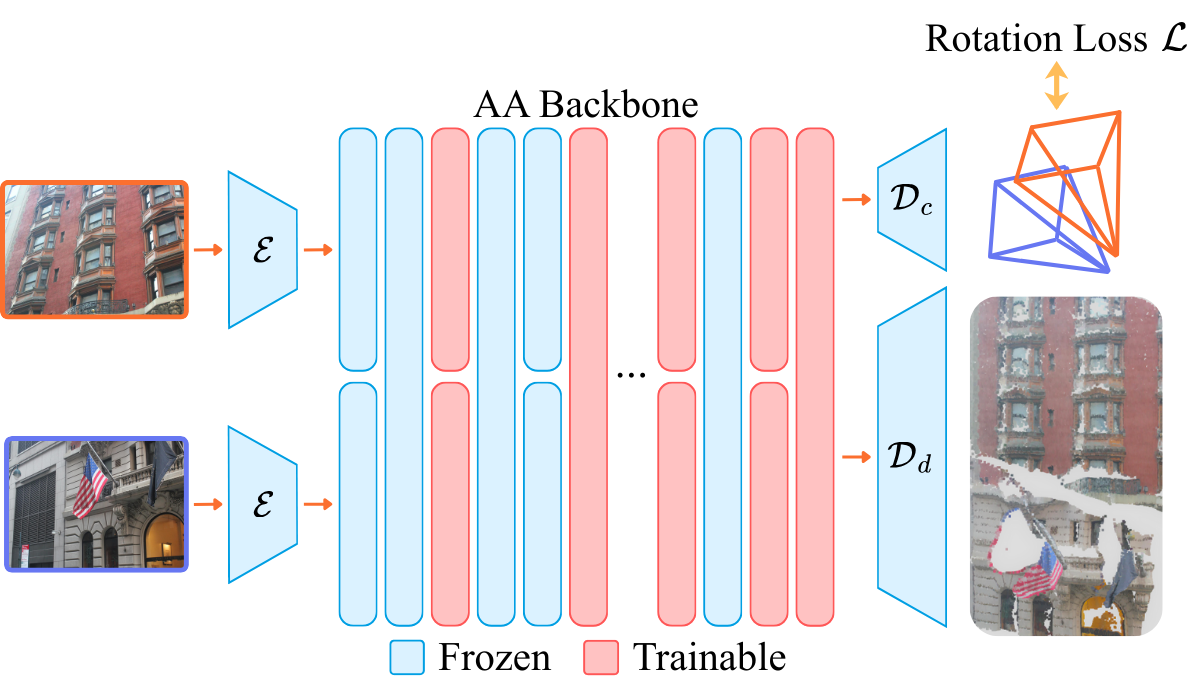
Do 3D foundation models have an emergent understanding of extreme-views?
The pre-trained VGGT model was trained primarily on overlapping images.
Surprisingly, when tested on non-overlapping image pairs, the model still produces plausible estimates of relative pose,
with nearly half of the pairs yielding a rotation error below 30°.
Careful fine-tuning of a small number of parameters substantially improves results, as shown above by the error distribution on our new relative pose in-the-wild benchmark (UnScenePairs-t).
Hover over the interactive canvas above to view random non-overlapping image pairs from our benchmark,
along with the rotation errors before and after our lightweight finetuning scheme.